


What is generative AI and how does it impact search?

Ever since OpenAI’s launch of ChatGPT, the topic of AI has dominated the topic of many technology discussions. The integration of ChatGPT into Bing drove a spike in Microsoft’s share price while Google’s awkward launch of Bard led to a drop in Alphabet’s stock. When Google seemed to have gotten the AI message right in their annual I/O conference, this time the stock rose.
Obviously, AI is really important for the future of technology, but many people simply don’t understand what specifically generative AI is other than that it seems to be really cool and a great tool to avoid writing long emails.
While I don’t think generative AI, formally a “large language model” or LLM is as magical as some think it is, I still believe it has immense potential to disrupt many paradigms of marketing that exist today. A poor LLM product, even one hated universally by users, will still cause incredible disruption to top-of-funnel SEO traffic within search until Google removes or modifies the product.
Additionally, if Google misses the mark and other search engines grab market share this will also cause a fair bit of disruption in existing traffic. I have shared quite a bit on this impact in prior newsletters, but for this update, I want to share more of a what with regards to this topic.
The product that exists in Google search today, which Google calls “Search Generative Experience” is a beta product and has many flaws. In order to understand those shortcomings and to predict how it might change, I think it’s helpful to dive into what a large language model really is and how it could be used in conjunction with search.
What is a Large Language Model?
A large language model (LLM) is a type of artificial intelligence (AI) algorithm that uses deep learning techniques and large data sets to understand, summarize, generate, and predict new content. This is why it is also called Generative AI.
To do this it uses natural language processing tasks, which include generating and classifying text, answering questions in a conversational manner, and translating text from one language to another.
Put more simply, it is a predictive text model that uses a snippet of text to calculate what the next snippet of text should be.
In this regard, an LLM is not nearly as complex an artificial challenge as something like self-driving in a car.
The LLM doesn't really understand any of the topics that is processing, it just uses statistics to stitch words together into answers. It can write a complex essay about a medical topic, but it doesn’t “understand” the topic, rather it calculates the probabilities of each word appearing after a prior word based on the prompts - translated into probabilistic statistics that it is given.
For example, if it processes the word “what”, it uses its algorithms to determine what the next word should be after that first word. The possibilities include words like “should”, “did”, “are”, “is”, but would not include words like “why” which very rarely would appear in any training material after the word “what.”
Its training material is the entire web, but its answers are limited by the max potential of words in a language. Adding additional training material wouldn’t change basic informational responses, but it could impact less popular topics or anything that requires recent knowledge.
This is why any move to block Google from crawling the web to train its modules would be unlikely to stop generative AI. It already knows most of what it needs to answer the majority of informational queries unless it requires recent evergreen knowledge.
Autonomous driving vs LLM
To put this comparison between cars and words into numbers: to successfully drive a car autonomously the algorithms use a vast amount of data from multiple cameras, radar, and sensors. It is estimated that cars create 1gb of data per second!
Contrasted with an LLM, there are about 450k in the full Webster’s unabridged dictionary while it is said that an average English speaker knows only about 50k words. Based on pure words, an LLM is working with a much smaller dataset.
As should be clear by now, an LLM is just a text prediction algorithm and is not really a search engine on its own. An LLM can’t do math on its own unless it has seen the precise formula (or similar) in its training modules.
Here’s an example, where it tried to translate my math query into text, but it still can’t do the math.
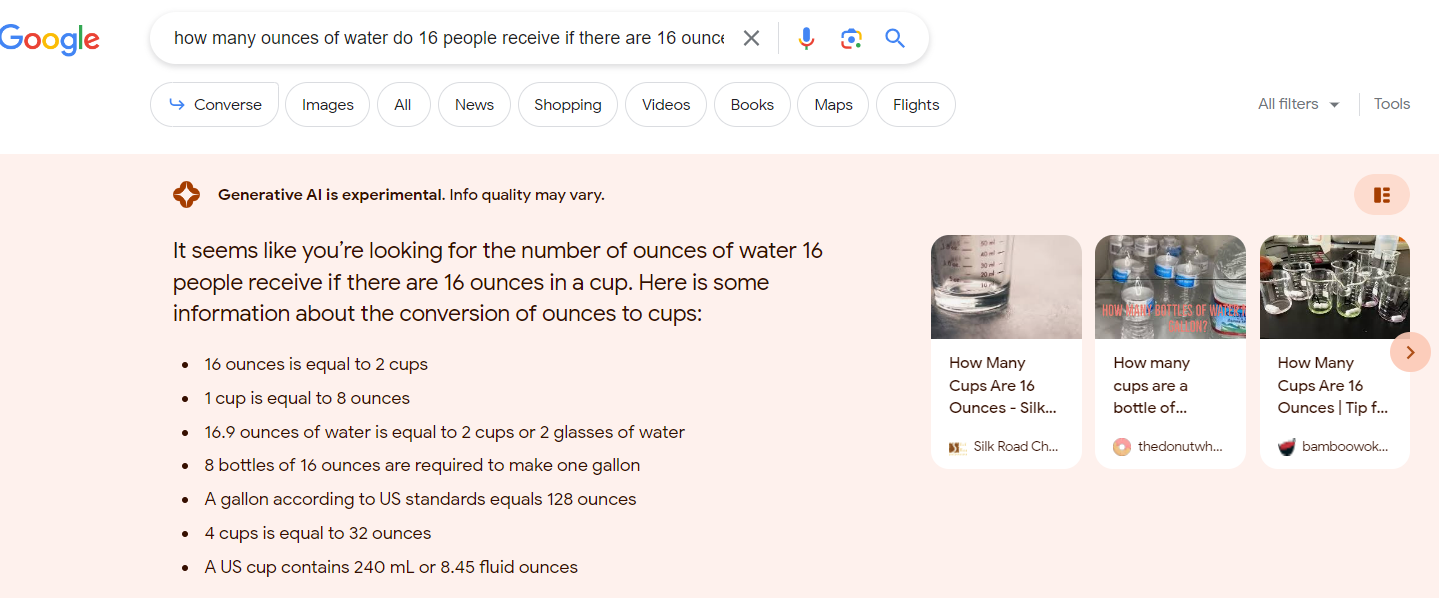
On this note, Google is actually in a better position to win on generative AI because it already has its core algorithms which are already great at processing logic. LLM + Google’s two decades of search prowess is an indomitable force. (Note: Google released an update to Bard today that addresses this issue.)
LLM in search
Back to LLM in search, writing text is a core use case of an LLM, but because it uses probabilities to write content it is specifically designed to write only average content. Anything better or worse than the average would be ignored in the training set. There is some element of randomization built into the algorithms to keep the content it produces from being completely boring and repetitive.
This makes it possible that the most amazing content could be created with an LLM, but it would require a degree of luck for that to happen due to it randomly including outlier words.
Integrated into search, the LLM writes average text in response to how it processes the query or prompt. For many informational prompts/queries this will be good enough to satisfy most users.
An LLM cannot replace what a search engine does when it queries a database, it only enhances its usefulness and potentially improves the user experience. By launching SGE, Google is extending what they already started by creating what they call featured snippets or knowledge graph that gives answers without the need to click into a website.
The primary difference between SGE and knowledge graph is that the latter is based on structured data which for the most part is accurate and will not embarrass Google while the former can produce a lot of responses that could cause backlash to Google.
This fear of embarrassment (and maybe a fear of hurting ad revenue) might have held Google back from integrating LLM’s in the past, but the launch of ChatGPT forced their hand. From a Google perspective, this is just an extension of what they already do, providing the user with an answer to what they seek as fast as possible.
I hope this rudimentary understanding of generative AI/LLM’s helps set the stage about what to expect as Google expands its SGE offering.
Part 2 of this newsletter update will expand into where I think Google will ultimately land with SGE and how it will impact websites. Thank you for reading!
As of today, your newsletter is one of the best read on that topic which I’m SO surprised not that many people are taking about or even seemed to care about. Phenomenal work. So much value. Can’t wait to see if all your predictions will be true …